{kind=link}
Иллюстрация: DALL-E
2024 год в Казахстане хоть и не носил официального статуса «года ИИ», но, судя по частоте упоминания, таковым был. О нём говорили все — начиная с Касым-Жомарта Токаева. А его фразу «предстоит довести до каждого жителя Казахстана пользу искусственного интеллекта», сказанную на презентации хаба AlemAi, можно сравнить с ленинским выражением про кухарку и государство. И вообще, судя по новостям, в конце прошлого года ИИ в Казахстане вызывал только восторг. Но после того как журналист наш сайт пообщался с разработчиками искусственного интеллекта, оказалось, что у него могут быть ещё и проблемы.
Главным ИИ-проектом прошлого года в Казахстане можно назвать языковую модель Kaz-LLM, над которой работали в первую очередь в Назарбаев Университете. Если конкретнее, то в его Институте интеллектуальных систем и искусственного интеллекта (ISSAI).
Одной из главных фишек модели называли то, что она прошла обучение на 150 миллиардах токенов — то есть слов и элементов слов на казахском, русском, английском и турецком языках. Исполнительный директор ISSAI Ербол Абсалямов в общении с журналистом наш сайт сравнил это с прочтением 150 миллионов книг, что не смог бы сделать ни один эксперт. А возможность полноценно использовать казахский язык подчёркивалась едва ли не при каждом упоминании языковой модели.
11 декабря 2024 года разработка Kaz-LLM была закончена, и её материалы передали Минцифры. По словам Абсалямова, создание Kaz-LLM позволило Казахстану попасть примерно в 20 стран на земле, имеющих собственные языковые модели для ИИ. О том, что иметь собственную LLM — это действительно круто, говорили и другие эксперты, причём ещё за несколько месяцев до внедрения.
Что же дальше? Следующим шагом в развитии ИИ стало создание визуально-языковой модели Oylan. Точнее, параллельным шагом, потому что Oylan обучали именно параллельно. В пилотном виде он был готов в минувшем январе.
«Я могу понимать и работать как с текстовой, так и с визуальной информацией, помогая пользователям с различными задачами, такими как анализ изображений, ответы на вопросы и генерация контента. Я обучен общаться на нескольких языках, включая казахский, русский, английский и турецкий, что делает меня особенно полезным для задач, требующих многоязычных возможностей», — рассказывает модель сама о себе по запросу «Кто ты?».
Именно Oylan был представлен на форуме Digital Almaty в конце января и стал одной из его, форума, звёзд. По словам Ербола Абсалямова, при работе над Oylan им очень повезло:
«Когда мы тренировали Kaz-LLM, то нужны были последние модели суперкомпьютеров. Таких в Казахстане, к сожалению, нет. И мы использовали облачные сервисы за пределами Казахстана. Мы сами начали изучать, набирать опыт работы моделей с большим объёмом данных на этих суперкомпьютерах. И нормальный процесс, когда ты провёл тренировку, запустил, вышла ошибка — переделываешь. Так вот с Oylan нам очень повезло! Тренировка с этой моделью прошла за один „выстрел“».
Всего на обучение новой модели ушло 42 дня. Хотя, как подчёркивает Ерлан Абсалямов, данных для её тренировок потребовалось гораздо больше, потому что речь шла не только про текст, но и про изображения.
По словам исполнительного директора ISSAI, сейчас эта модель имеет возможность работать с максимальным количеством данных на казахском среди всех подобных «механизмов». Естественно, мы не могли не протестировать работу Oylan лично: как с текстом, так и с картинками. В обоих случаях мы использовали бесплатные версии.
В качестве теста мы попросили модель перевести:
- С казахского на русский — вступление статьи казахской редакции наш сайт о фильме «Меня зовут Кожа».
- С русского на казахский — вступление статьи русской редакции наш сайт о Кенесары-хане.
По оценке журналистов казахской редакции наш сайт, с переводом на русский модель справилась лучше, хотя и допустила пару огрехов. С переводом на казахский получилось хуже. В частности, ИИ нарушил правила построения предложений в казахском языке и в некоторых случаях не использовал буквы казахского алфавита. Например, в слове қазақ.
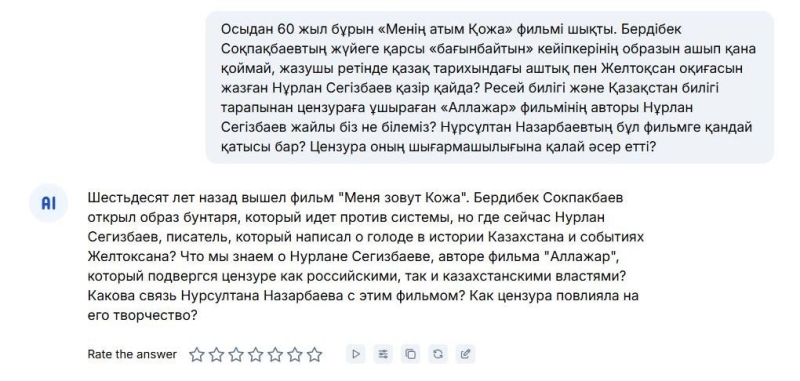
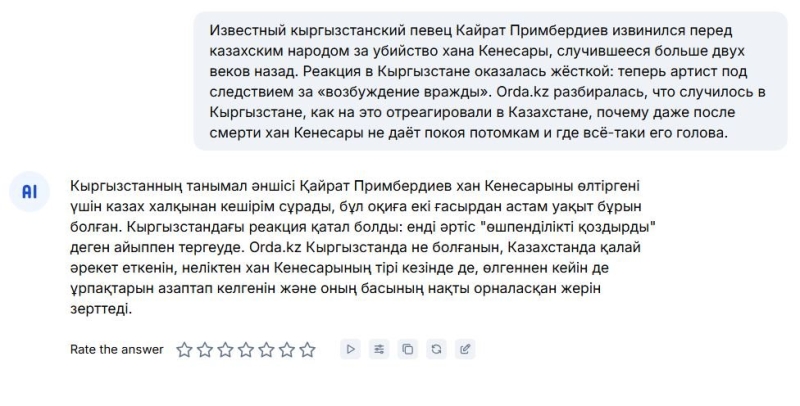
Для сравнения: ChatGPT те же самые тексты перевёл так:


Как видно, он всё-таки с задачей справился лучше.
С описанием картинок у Oylan всё получилось хуже. Например, такое описание на казахском дал ChatGPT снимку здания гостиницы «Казахстан» авторства фотографа наш сайт.

Модель Oylan описания этого же снимка нам не дала.

Хотя когда разработчики демонстрировали её возможности на форуме Digital Almaty и загружали карту Казахстана, описание таки было, и именно на казахском.
Но в конце концов ИИ на то и интеллект, чтобы обучаться. Возможно, через несколько месяцев Oylan перестанет путать правила и буквы. И вообще выйдет из статуса пилотного проекта, которым он до сих пор значится. Потому что:
«В настоящее время Oylan — это закрытая модель, доступная для взаимодействия на платформе ISSAI Playground, где разработчики могут использовать API для создания минимально жизнеспособных продуктов (MVP). Playground работает как коммерческий проект, поддерживающий финансовую устойчивость ISSAI: каждому пользователю, предоставляется 250 000 бесплатных токенов, а для дополнительного использования предусмотрена подписка. Однако и платформа, и сама модель требуют значительных инвестиций для покрытия затрат на персонал и вычислительные ресурсы, необходимые для дальнейшего обучения и развертывания», — говорится в официальном комментарии от ISSAI.
Под сухим термином «вычислительные ресурсы» имеются в виду как раз те самые облачные суперкомпьютеры, с помощью которых учили казахстанский ИИ. И именно с ними могут возникнуть проблемы.
«У нас заканчивается аренда облачных хранилищ. Если нас дальше обеспечат финансированием или проспонсируют, то мы готовы и дальше развиваться. И тогда мы придём к мультимодальной языковой модели. Если не будет денег, то у нас есть свои маленькие пятилетние суперкомпьютеры, на которых всё это размещено. Но все хотят этим пользоваться. И в итоге всё может треснуть, пойти по швам. А мы вернёмся к тому, что делали ранее — к научно-исследовательской работе», — признался в общении с журналистом наш сайт Ерлан Абсалямов.
Откуда деньги на разработку «казахстанского ChatGPT» деньги брались раньше, в ISSAI ответили так:
«Проект Oylan стал возможен благодаря постоянной поддержке фонда развития NIS и NU — эндаумент-фонда Назарбаев Университета, финансируемого за счёт частных средств».
Какими были денежные затраты на создание Oylan, в ISSAI не уточнили, но отметили, что сам институт лишь платил зарплату команде разработчиков из 13 человек. Причём подчеркнули, что оклады у них в среднем соответствуют рынку РК и ниже международных стандартов.
А как же Минцифры? Мы спросили у представителей ISSAI о поддержке со стороны профильного ведомства и получили такой ответ:
«Проект Oylan и платформа ISSAI PlaISSAIyground были разработаны исключительно командой, без внешнего участия, за исключением использования вычислительных ресурсов, предоставленных спонсорской компанией. Это спонсорство было организовано при содействии Министерства цифрового развития».
То есть МЦРИАП всё-таки в появлении Oylan свою роль сыграл. По поводу того, планирует ли министерство участвовать в жизни и развитии модели, мы направили официальный запрос. На конкретный вопрос: «Какую поддержку, в том числе финансовую, МЦРИАП оказывало разработчикам нейросети Oylan?» в министерстве не ответили ничего. Зато там рассказали о других казахстанских проектах в области ИИ, которые поддержку от ведомства точно получили. О них мы расскажем в следующих публикациях.
Читайте также: